
티스토리 뷰
<<Collection>>
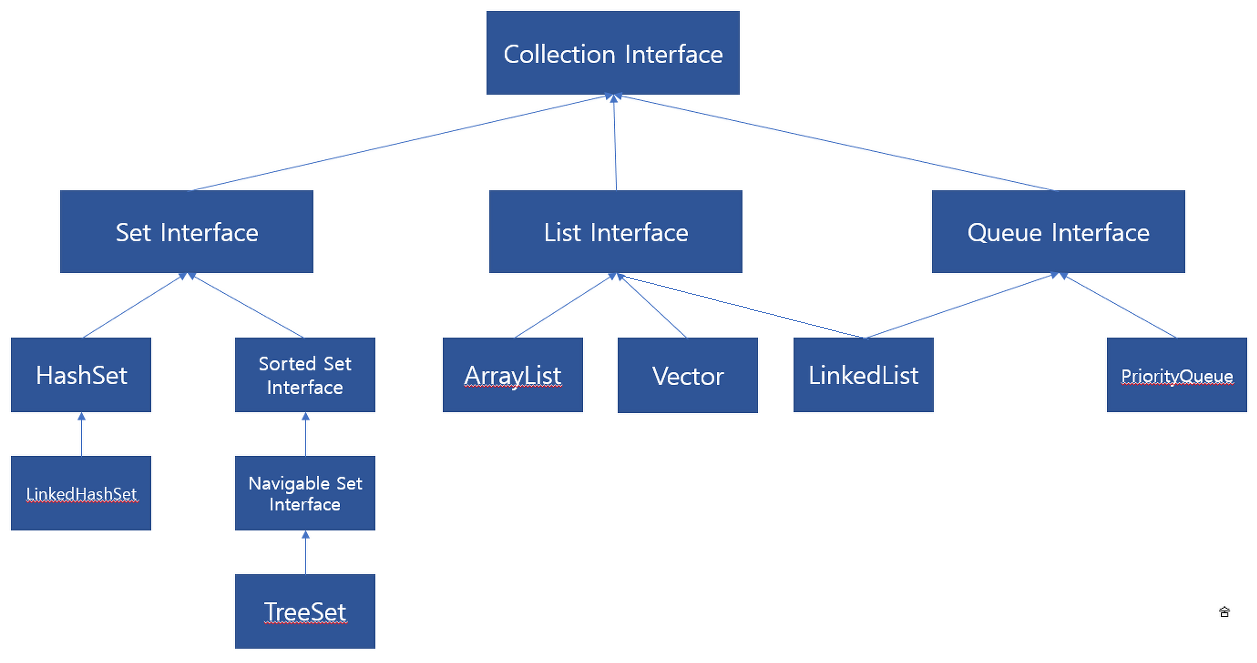
1. <<Set>>
# HashSet
특징:
- 순서 X
- 중복 X
- Null 허용
- get() X
- Thread-safe 보장 X
* HashSet 내부적으로는 Hashmap으로 구현되어 있기 때문에 HashTable과 유사한 자료구조로 데이터 저장한다.
그래서 Key Object에 저장하고 싶은 객체를 저장하고, Value Object에는 dummy data를 넣어둔다.
*순서가 보장되지 않은 이유
인덱스 = (hashCode % 버킷의 수)
HashCode와 엔트리 개수, 로드팩터에 따라 map에 저장되는 순서가 계속 바뀌기 때문이다.
시간 복잡도
- add : O(1)
- contains: O(1)
- next: O(h/n) * h: 해시 버킷의 사이즈, n: HashSet에 저장되는 데이터의 사이즈
# TreeSet
특징:
- 순서 정렬
- 중복 X
- 느림
- get() X
- Thread-safe 보장 X
시간 복잡도
- add : O(log n)
- contains: O(log n)
- next: O(log n)
2. <<List>>
# ArrayList
특징:
- 순서 O
- 중복 O
- 데이터의 인덱스를 가지고 있어 데이터 검색 시 빠름 (탐색 빠름)
- 배열이 동적으로 늘어나는 것이 아니라 용량이 꽉 찼을 경우, 더 큰 용량의 배열을 만들어 옮김
(복사가 일어남) -> 대량일 경우 성능 저하 => 중간에 추가, 삭제가 빈번하게 일어나면 비효율적임
- 순차적으로 삽입/ 삭제하는 경우 LinkedList보다 빠름
- 비효율적인 메모리 사용
- Thread-safe 보장 X
시간 복잡도
- add: O(1)
- remove: O(n)
- get: O(1)
- contains: O(n)
# LinkedList
특징:
- 순서 O
- 중복 O
- 각 노드가 이전 노드와 다음 노드의 상태만 알고 있음
- 데이터 추가/ 삭제 시 빠름
- 비순차적인 데이터의 추가 또는 삭제에 시간이 많이 걸림
- 데이터 검색 시 처음부터 노드를 순회하기 때문에 느림
(ArrayList는 인덱스를 통해서 검색하는데, LinkedList는 Head에서부터 해당 원소까지 검색해야 하기 때문에 O(n)에 찾음 더느림)
- Thread-safe 보장 X
시간 복잡도
- add: O(1)
- remove: O(1)
- get: O(n)
- contains: O(n)
# Vector
- 과거에 대용량 처리를 위해 사용되었지만, 내부에서 자동으로 동기화 처리가 일어나 비교적 성능이 좋지 않고 무거워서 잘 쓰이지 않음
3. <<Queue>>
# PriorityQueue
특징:
- 일반적인 Queue는 FIFO 구조를 가지지만, PQ는 기본적으로 정수형에 대해선 오름차순 정렬함!
- Heap 구조를 가짐
- 정렬 기준에 따라 MaxHeap을 만들 수 있고, MinHeap을 만들 수 있음
- compare interface 구현 (comapreTo() 우선순위 method)
시간 복잡도
- offer(): O(log n)
- peek(): O(1)
- poll(): O(log n)
- size:(): O(1)
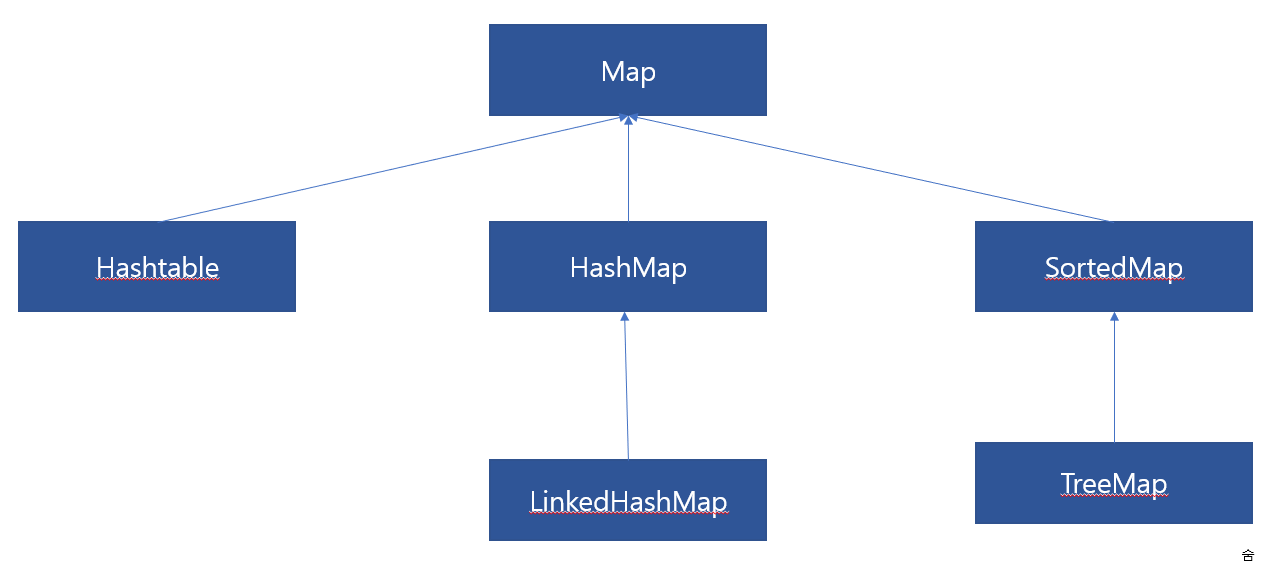
4. <<Map>>
=> 직접 상속 X
(독립적인 인터페이스 구현되어 있음: "일반적인 컬렉션들과의 디자인 구조차이")
# HashMap
특징:
- 키 중복 X
- {key, value} 형태
- Key값의 순서 X
- 객체의 hashCode() 메서드의 리턴 값을 기반으로 동작
- 해시 충돌의 경우를 대비해 equals() 메서드까지 사용하여 key 값이 같은 경우에 Value return
- 다른 Map에 비해 빠른 탐색 시간 (해시함수 사용하기 때문)
- Null 허용
- Thread-safe 보장 X
시간 복잡도
- get: O(1)
- containsKey: O(1)
- next: O(h/n) * h: 해시 버킷의 사이즈, n: HashSet에 저장되는 데이터의 사이즈
# TreeMap
특징:
- 키 중복 X
- {key, value} 형태
- RedBlack Tree로 저장하여 관리 => Key값의 순서 정렬
- 객체의 hashCode() 메서드의 리턴 값을 기반으로 동작
- key 값으로 사용할 클래스에 Comparator 인터페이스를 구현하면 사용자가 정렬된 순서를 조정할 수 있음
- 데이터를 내부적으로 RB-Tree 형태로 관리 탐색/추가/삭제 시 HashMap보다 느림
- Null X
- Thread-safe 보장 X
시간 복잡도
- add : O(log n)
- containsKey: O(log n)
- next: O(log n)
# LinkedHashMap
특징:
- HashMap 확장한 클래스
- HashMap과 다른 점은 입력한 순서를 기억
- 연결 리스트 구조를 가짐
- 불필요하게 Linked-list를 유지하는 비용이 생길 수 있음
시간 복잡도
- add : O(1)
- containsKey: O(1)
- next: O(1)
# Multimap
특징:
- google에서 제공하는 다양한 자료구조와 유틸리티들을 모아 둔 라이브러리에 guava에 Multimap이 존재함
- map과 비슷하지만 각 키값에 대해서 복합적인 값을 가질 수 있음(Key값이 중복 가능)
- 사용할 경우
1. 저장된 데이터들을 정렬해야 할 경우
2. 많은 자료들을 저장하고, 특정 자료에 대해 검색을 빠르게 해야 할 경우
3. map과 동일하나, key값이 중복된 원소를 가질 수 있는 경우
+참고자료
https://www.grepiu.com/post/9
https://soft.plusblog.co.kr/70
https://javainfinite.com/java/hashmap-vs-hashset-vs-hashtable-hashmap-hashtable-examples/
https://velog.io/@sweet_sumin/Map%EA%B3%BC-Multimap-TreeMap-HashMap-LinkedHashMap-%EC%B0%A8%EC%9D%B4
피드백은 언제나 환영입니다 :) 🌳
'Java is my life > 공부하다 지식공유' 카테고리의 다른 글
| HashMap 공부중(1) - 1개의 Key에 여러개 Value (2) | 2022.10.21 |
|---|---|
| 메서드 반환타입 void와 return; (0) | 2022.10.06 |
| 2차원 배열 리스트 (0) | 2022.10.02 |
- Total
- Today
- Yesterday
- JAVA 할인행사
- 정보통신산업진흥원
- 자바 return
- 프로그래머스 롤케이크자르기
- JAVA 컬랙션
- AI교육
- 프론트엔드
- 플그 멀리 뛰기
- java 멀티버스
- HashMap 자바
- 16234 마법사 상어와 파이어볼
- Java 멀리 뛰기
- 18868 멀티버스 java
- level2 롤케이크 자르기
- IT개발캠프
- 백엔드
- AI-WEB 교육
- 프로그래머스 할인행사
- 메서드형 void
- 유데미
- 백준 멀티버스 자바
- NIPA
- AI캠프
- 할인행사 자바
- 1개 Key 여러개 Value
- 서울ICT이노베이션
- 멀티버스 java
- 마법사상어와 파이어볼
- 멀리 뛰기 자바
- java 마법사 상어와 파이어볼
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |