
티스토리 뷰
나는 파이썬 외의 다른 언어를 사용할 줄 알기 때문에 아주 기초적인 건 정리하지 않았다. (생판 모르는 사람이 보면 이해 안 되는 부분이 있을 수도 있다.)
입력받기
1. 입력 값 정수 한 개
input()
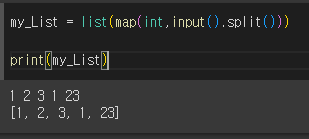
2. 공백 기준으로 정수 여러 개
arr_list = list(map(int, input().split('')))
# input().split('')은 공백을 기준으로 분리하고 리스트를 만듦
# map(int, input.split(''))은 만들어진 리스트를 순회하면서 각 원소에 대한 자료형을 int로 변환해줌
# input()은 모두 str이기 때문에
# map의 겉 부분에 list() 한 이유는 map 함수는 literable을 반환하기 때문에 list를 사용하기 위해 감쌈
출력하기
print()
print(i, end = ' ')
# 한 줄에 결과값을 계속 이어서 출력하려면 end를 사용해 끝 문자를 지정해야 함
# end의 초기값은 줄바꿈(\n) 이다.
산술 연산
* : 곱셈
/: 나눗셈 (float 형)
7 / 5 # 1.4//: 나눗셈의 몫
5 // 3 # 1%: 나눗셈의 나머지
5 % 3 # 2divmod(): 나눗셈의 몫과 나머지(튜플 형식으로 나눗셈의 몫, 나머지를 한 번에 가져온다.)
num1, num2 = divmod(5,3) # num1 = 1, num2 = 2**: 거듭제곱
3 ** 2 # 3의 2제곱
자료형
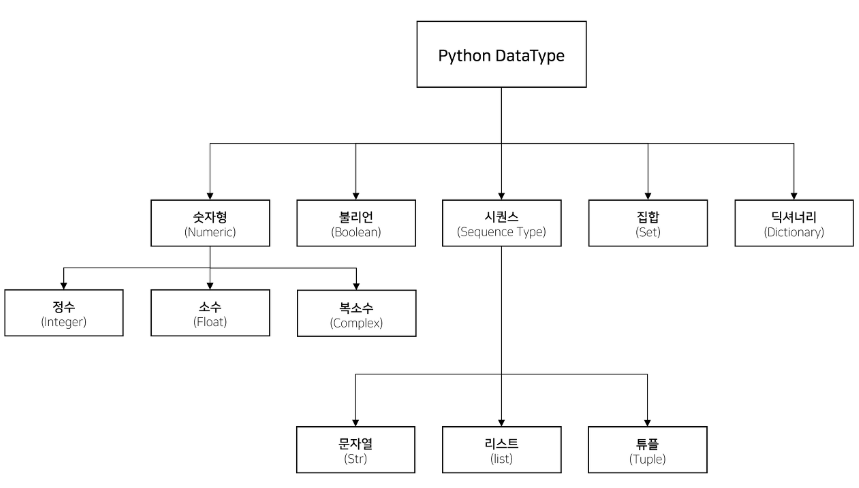
자료형이란? 데이터의 성질을 나타내는 것으로, 주로 5개의 자료형이 사용된다.
숫자형(Numeric), 블리언(Boolean), 시퀀스(Sequence Type), 집합(Set), 딕셔너리(Dictioinary)
파이썬에는 type() 함수로 특정 데이터의 자료형을 알아볼 수 있다.
type(10) # <class 'int'>
type(2.718) # <class 'float'>
type("hello") # <class 'str'>
변수
파이썬은 동적언어로 분류되는 프로그래밍이기 때문에 변수의 자료형을 상황에 맞게 자동으로 결정한다.
리스트(List)
다수 데이터를 저장하는 데 사용된다. [ ] 괄호를 사용하고 리스트에 포함된 데이터는 "요소(Element)"라고 부른다.
리스트에서 각 요소는 위치(Index)를 가지고 있으며 이 위치를 통해 개별 요소에 접근할 수 있다.
동일한 자료형 Element를 가질 수 있고, 다른 자료형의 Element를 가질 수 있다.
또한, 리스트는 객체이다.

list = [1, 2, 3, 4, 5] # 리스트 생성
len(list) # 리스트의 길이 출력
list(x) # x번째 원소에 접근
list[x] = 99 # x번째 원소에 값 대입
list[-x] = 뒤에서부터 x번째 원소에 접근
슬라이싱(Slicing)
파이썬 리스트에서 원하는 부분을 추출(슬라이싱) 하기 위해서 인덱스의 숫자를 적어준다.
: (콜론) 기점으로 왼쪽, 오른쪽에 숫자를 적어준다.
왼쪽 숫자는 시작 인덱스(오프셋 offset)를 나타낸다.
오른쪽 숫자는, 우리가 추출을 끝내려는 인덱스보다 1이 더 큰 수이다.
- [:] 처음부터 끝까지
- [start:] start오프셋(인덱스)부터 끝까지
- [:end] 처음부터 end-1 오프셋(인덱스)까지
- [start : end] start오프셋부터 end-1 오프셋(인덱스)까지
- [start : end : step] step만큼 문자를 건너뛰면서, 위와 동일하게 추출
list = [1, 3, 5, "숨", 1.32]
list[0:2] # 인덱스 0부터 1까지 얻기 [1, 3]
list[1:] # 인덱스 1부터 끝까지 얻기 [3, 5, "숨", 1.32]
list[:3] # 처음부터 인덱스 2까지 얻기 [1, 3, 5]
list[:-1] # 처음부터 마지막 원소의 1개 앞까지 얻기 [1, 3, 5, "숨"]
list[:-2] # 처음부터 마지막 원소 2개 앞까지 [1, 3, 5]
튜플 (tuple)
리스트와 거의 비슷하며 다른 점은 () 괄호를 사용하고, Element 값을 바꿀 수 없다.
안정성이 중요한 상황에서 사용된다.

tuple = (1, 2, 'a', 'b')
tuple[0] # 1
딕셔너리(Dictionary)
딕셔너리는 키(key) - 값(value)이 쌍으로 구성된다. (자바의 Map과 비슷)
키는 값을 식별하는 역할을 하며, 주어진 키를 이용해 키에 해당하는 값을 찾을 수 있다.
키의 값은 유일하여 동일한 키를 사용할 수 없으며, 값은 중복이 가능하다.
순서의 보장이 없다. 또한, {}를 사용한다. {key:value}
dic = {'age': 8} # 딕셔너리 생성
dic['age'] # 8출력 -> 값을 가져오기 위해서 키 값을 부름
dic['name'] = '수민공주' # 새 원소 추가
print(dic) # {'name': '수민공주', 'age': 8}
dic.key() # 모든 키를 모아 리스트 형태로 변환함
dic.value() # 모든 값을 모아 리스트 형태로 변환함
집합(Set)
집합은 중복된 값이 없는 유일한 값들의 모임이다. 집합은 순서가 없는 데이터 구조이기 때문에 인덱스로 접근할 수 없다. 대신, 집합에 특정 값이 포함되어 있는지 확인이 가능하고 다양한 연산을 지원하는 기능을 가지고 있다.(교집합, 합집합 차집합 등) 또한, {}를 사용한다. {1 , 2 , 3, 4 }
자바의 set과 비슷하다.
if문
if문을 쓸 때에는 공백 문자가 중요하다. (들여 쓰기)
공백 문자 대신 tab 문자를 사용해도 되지만, 파이썬에서는 공백을 권장한다. 그리고 한 단계 더 들여 쓸 때마다 공백 4개씩을 추가하는 것이 일반적이다.
if hungry:
print("really hungry")
else:
print("No")
print(" I'm stuffed")
for문
for 변수 in 객체:
실행문
- 객체는 문자열, 리스트, 튜플, 딕셔너리를 의미함(대체적으로)
- 변수는 객체의 첫 인덱스에 해당하는 값부터 마지막 인덱스에 해당하는 값까지 차례대로 정의함
for in range(시작값, 끝값, 증감크기):
실행문
- 변수가 시작값부터 끝값 -1까지 증감크기 간격으로 증가하면서 실행문을 돌게 됨
- 증감크기를 생략하거나, 시작값과 증감크기를 함께 생략할 수 있음
for 관련 함수 else
- else: for문이 정상적으로 종료된 뒤 실행됨, break로 인해 for문이 종료된 경우 실행되지 않음
for i in [1,2,3]:
print(i)
else:
print('끝')
# 출력값: 1, 2, 3, 끝
for i in [1, 2, 3]:
if i == 2:
break
print(i)
else:
print('끝')
# 출력값: 1
리스트 내포 (리스트 내부에서도 for문이 사용 가능함)
[표현식 for x in 객체 1 if 조건문 1
for y in 객체 2 if 조건문 2
....
for 변수 n in 객체 n if 조건문 n]
- if 조건문은 생략 가능함
함수
특정 기능을 수행하는 일련의 명령들을 묶어 하나의 함수로 정의할 수 있다.
def hello():
print("hihi")
hello() # hihi
def greeting(object):
print("hihi" + object)
greeting("Im sum") # hihi Im sum
클래스
개발자가 직접 클래스를 정의하면 독자적인 자료형을 만들 수 있다. 또한, 클래스에는 그 클래스만의 전용 함수(메서드)와 속성을 정의할 수도 있다.
파이썬에서는 class라는 키워드를 사용하여 클래스를 정의한다.
clss 클래스 이름:
def __init__(self, 인수, ...): # 생성자
def 메서드 이름 1(self, 인수, ...): # 메서드 1
def 메서드 이름 2(self, 인수, ...): # 메서드 2클래스 정의에는 __init__라는 특별한 메서드가 있는데, 클래스를 초기화하는 방법을 정의한다.
이 초기화용 메서드를 생성자라고 하며, 클래스의 인스턴스가 만들어질 때 한 번만 불린다.
또한, 파이썬에서 메서드의 첫 번째 인수로 자신(자신의 인스턴스)을 나타내면 self를 명시적으로 쓰는 것이 특징이다.(다른 언어 쓰던 사람은 이처럼 self 쓰는 규칙이 신박할 수 있다.)
clss Man:
def __init__(self, name):
self.name = name
print("Initialized!")
def hello(self):
print("hi" + self.name)
def bye(self):
print("bye" + self.name)
m = Man("Sum Lee")
m.hello()
m.bye()
$ python man.py (파이썬 터미널창 실행)
Initialized!
hi Sum Lee
bye Sum LeeMan이라는 클래스에서 m이라는 인스턴스(객체)를 생성한다.
Man의 생성자는 name이라는 인수를 받고, 그 인수로 인스턴스 변수인 self.name을 초기화한다. 파이썬에서 self.name처럼 self 다음으로 속성 이름을 써서 변수를 작성하거나 접근할 수 있다.
Python
class Point:
def__init__(self,r,c):
self.r = r
self.c = cJava
class Point{
int r;
int c;
public Point(int r, int c){
this.r = r;
this.c = c;
}
}
이렇게 같은 코드이다.
헷갈려서 완벽하게 이해하기 위해.. 구현한 코드들이다.
넘파이
딥러닝을 구현하면 배열이나 행렬 계산이 많이 등장한다. 넘파이의 배열 클래스인 numpy.array에는 편리한 메서드가 많이 준비되어 있어, 딥러닝을 구현할 때 이들 메서드를 이용한다.
넘파이의 특징 중 하나가 n차원 배열(ndarray) 객체이다. 이 객체는 빠르고 유연한 자료형이며, 수학식에서 행렬 연산과 비슷한 연산을 할 수 있다. 즉, 성분별 계산을 할 수 있다.
import numpy as np # 넘파이는 외부 라이브러리기 때문에 import 해야한다.
넘파이 배열을 만들 때 np.array() 메서드를 사용한다.
np.array()는 파이썬의 리스트를 인수로 받아 넘파이 라이브러리가 제공하는 특수한 형태의 배열(numpy.ndarray)을 반환한다.
x = np.array([1.0, 2.0, 3.0])
print(x) # [1.,2.,3.]
넘파이 산술 연산할 때 주의할 점은 계산할 배열의 수를 맞춰야 한다.
x = np.array([1.0, 2.0, 3.0])
y = np.array([3.0, 5.0, 7.0])
x + y # array([4., 7., 10.])
x * y # array([3., 10., 21.])
넘파이 배열은 원소별 계산뿐만 아니라 넘파이 배열과 수치 하나(스칼라값)의 조합으로 된 산술 연산도 수행할 수 있다. 이 경우 스칼라값과의 계산이 넘파이 배열의 원소별로 한 번씩 수행된다. 이러한 기능을 브로드 캐스트라 한다.
x = array([4.0, 7.0, 10.0])
x / 2.0 # array([2., 3.5, 5.])
넘파이의 N차원 배열
A = np.array([[1,2],[3,4]])
A.shape # (2,2) 2*2 행렬이라고 형상을 알려줌
A.dtype # dtype('int64') 원소의 자료형을 알려줌
B = np.array([[3,0],[0,6]])
A+B # array([[4,2],[3,10]])
A*B # array(([3,0],[0,24]))
A * 10 # # array([[10,20],[30,40]])1차원 배열은 벡터, 2차원 배열은 행렬이라고 부른다. 또한 벡터와 행렬을 일반화한 것을 텐서라고 한다.
3차원 배열 이상을 다차원 배열이라고 한다.
브로드캐스트
일반적으로 Numpy에서는 모양이 다른 배열끼리 연산이 불가능하다. 하지만 브로드캐스팅이라는 똑똑한 기능을 사용한다면 가능하다.
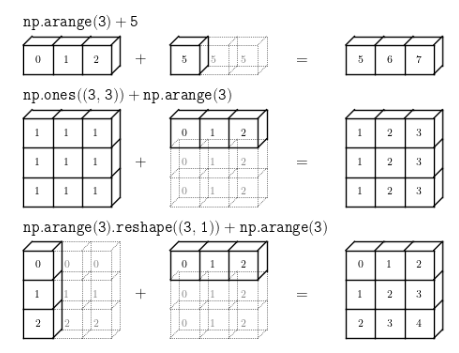
브로드캐스팅은 어떤 조건만 만족한다면 모양이 다른 배열끼리의 연산도 가능하게 해 주며, 모양이 부족한 부분은 확장하여 연산을 수행할 수 있도록 하는 것이다. 확장 또는 전파한다는 의미의 브로드캐스팅의 간단한 예는 행렬과 스칼라 값을 계산하는 것이다. (스칼라 값은 우리가 아는 일반적인 상수이다.)
브로드캐스팅이 일어날 수 있는 조건
1. 차원 크기가 1일 때 가능하다. (세 번째 그림 만족)
두 배열 간의 연산에서 최소한 하나의 배열의 차원이 1이라면 가능하다.
2. 차원의 짝이 맞을 때 가능하다.
차원에 대한 축의 길이가 동일하면 브로드 캐스팅이 가능하다. (두 번째 그림 만족)
'ICT-AI-WEB 교육' 카테고리의 다른 글
| Keras (0) | 2023.09.01 |
|---|---|
| 원-핫 인코딩(One-hot encoding) (1) | 2023.08.31 |
| 인공지능 딥러닝 알고리즘 (0) | 2023.08.29 |
| 생성형(Generative) AI란? (0) | 2023.08.24 |
- Total
- Today
- Yesterday
- 16234 마법사 상어와 파이어볼
- 메서드형 void
- 멀리 뛰기 자바
- level2 롤케이크 자르기
- 18868 멀티버스 java
- 플그 멀리 뛰기
- 백준 멀티버스 자바
- 프론트엔드
- NIPA
- AI-WEB 교육
- 자바 return
- JAVA 컬랙션
- 유데미
- 정보통신산업진흥원
- java 멀티버스
- AI교육
- Java 멀리 뛰기
- 할인행사 자바
- AI캠프
- 멀티버스 java
- 서울ICT이노베이션
- 프로그래머스 롤케이크자르기
- 프로그래머스 할인행사
- 1개 Key 여러개 Value
- java 마법사 상어와 파이어볼
- HashMap 자바
- 마법사상어와 파이어볼
- JAVA 할인행사
- IT개발캠프
- 백엔드
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |